

目次
以前の記事で紹介したモデルが使い物にならなかった
こんにちは。
AI coordinatorの清水秀樹です。
以前紹介したリアルタイム映像からの美人女優検出で作成した学習モデルは、とりあえず学習モデルの作成方法を学ぶことを目的としていたため、精度は二の次としていました。
今回、人様の前でこの内容を紹介することになり、久しぶりに学習モデルを作成して実践してみたところ、
想像以上に精度が悪すぎました。(; ・`д・´)
はっきりって使い物になりませんでした。


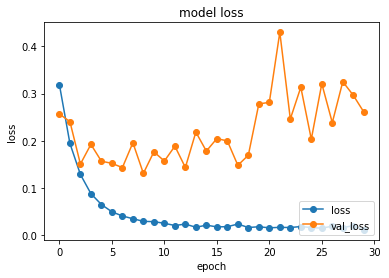
図の通り、nb_epoch = 4 からいきなり過学習になります。
というわけで、改めて学習モデルの作り方を見直したので、その内容の紹介になります。
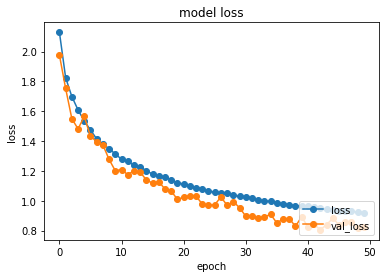
ちなみに以下が、見直した時の結果です。


見違えるぐらい良くなりました。
今回学習して学んだことは、筆者の備忘録として細かく記載していきたいと思います。
参考にしたサイト
定番のConvolutional Neural Networkをゼロから理解する
こちらのサイトは「Convolutional Neural Network(CNN)」を図解でわかりやすく表現してくださっているサイトです。
畳み込み層をイメージするならこちらのサイトが参考になります。
続いて以下のサイトです。
こちらのサイトはKerasを使用する上での説明を詳しく紹介してくださっています。
また、以下のサイトも参考にさせて頂きました。
ディープラーニングのCNNとKerasを対応づけてみたーその1機械学習(8日追加)
畳み込み層を簡単にイメージアップする上で参考になります。
最後に紹介するサイトは4次元テンソルの考え方や、畳み込み層のフィルタの可視化なんかを紹介してくださっているサイトになります。
以上、貴重な情報提供ありがとうございます。
精度が低い1番の理由は学習データ量が少なすぎたこと
5人の美人女優たちの画像を集めていましたが、各人の学習用データの枚数は以下も枚数で実施していました。





上戸彩 :229枚
剛力彩芽:168枚
渡辺麻友:143枚
佐々木希:56枚
新垣結衣:138枚
前回はテキトーにやったとはいえ、あまりにも画像数が少なすぎたようです。
ということで、画像枚数を増やせば良いわけですが、前回もgoogle様の画像検索から一通りダウンロードして画像を集めた経緯があります。
そのため、これ以上新しい画像を準備することは難しいと判断。
そこで閃いたの方法が、
コピーして増やせば良いじゃん!( ・`ー・´) + キリッ
効果があるかどうか不明でしたが、同じ画像でも少ないよりは良いと判断し、コピーという非常に楽な方法で画像枚数を増やしました。
上戸彩 :229枚 → 458枚
剛力彩芽:168枚 → 504枚
渡辺麻友:143枚 → 572枚
佐々木希:56枚 → 560枚
新垣結衣:138枚 → 552枚
実はこれが一番効果がありました。
畳み込みニューラルネットワークをちょっと勉強してみた
テキトーに作り上げていた畳み込み層(Convolution2D等)のパラメータを意識してモデルを作り変えました。
以下は、以前作成したモデル
def build_model(in_shape):
model = Sequential()
model.add(Convolution2D(32, 3, 3, border_mode='same', input_shape=in_shape))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Convolution2D(64, 3, 3, border_mode='same'))
model.add(Activation('relu'))
model.add(Convolution2D(64, 3, 3))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(nb_classes))
model.add(Activation('softmax'))
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
return model
以下は、今回作り変えたモデル
def build_model():
model = Sequential()
#畳み込み層の作成
#1層目の追加 1024個の層を最初に作り、フィルター3*3のフィルターを32個作成
model.add(Convolution2D(32, 3, 3, border_mode="same", input_shape=in_shape))
model.add(Activation("relu"))
#2層目の畳み込み層
model.add(Convolution2D(32, 3, 3, border_mode="same"))
model.add(Activation("relu"))
#プーリング層
model.add(MaxPooling2D(pool_size=(2, 2)))
#Dropoutとは過学習を防ぐためのもの 0.25は次のニューロンへのパスをランダムに1/4にするという意味
model.add(Dropout(0.5))
#3層目の作成
model.add(Convolution2D(64, 3, 3, border_mode="same"))
model.add(Activation("relu"))
#4層目の作成
model.add(Convolution2D(64, 3, 3, border_mode="same"))
model.add(Activation("relu"))
#プーリング層
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
#5層目
model.add(Convolution2D(128, 3, 3, border_mode="same"))
model.add(Activation("relu"))
#6層目
model.add(Convolution2D(128, 3, 3, border_mode="same"))
model.add(Activation("relu"))
#プーリング層
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
#平坦化
model.add(Flatten())
#7 全結合層 FC
model.add(Dense(100))
model.add(Activation("relu"))
#Dropout
model.add(Dropout(0.5))
#8層目 引数nub_classesとは分類の数を定義する。
model.add(Dense(nub_classes))
model.add(Activation('softmax'))
#ここまででモデルの層完成
#lossは損失関数を定義するところ
model.compile(loss="categorical_crossentropy",
metrics = ["accuracy"],
optimizer = "adam"
)
return model
自分なりの解釈
自分なりに解釈した内容を備忘録として残して見ようと思います。(すぐ忘れるので)
基本的にモデルの層の数は好きなように決めて良い。(多分)
とはいえある一定のルールはあるはず。
ただ、明確に何層まであれば良いのかとか、Convolution2Dの引数の値の正当性なんかを紹介しているサイトは見つからなかった。
とりあえず参考書なんかにあるサンプルを参考に作ってみたが、この辺のモデル構築は企業機密なのかもしれない。
各引数の意味
model.add(Convolution2D(32, 3, 3, border_mode=”same”))
→32は畳み込み層の数。
→3,3はフィルターサイズこの場合は3×3。。
model.add(MaxPooling2D(pool_size=(2, 2)))
→Convolution層の後に入力データを扱いやすくするために、情報を圧縮する。
batch_size
→学習データから設定したサイズごとにデータを取り出し、計算を行う。
nb_epoch
→モデルを学習するエポック数(学習データ全体を何回繰り返し学習させるか)を指定する。
とりあえずメモでした。(適当に理解)
ソースの紹介
学習モデルを作成するソース全容です。
継ぎ接ぎで作成しているため、ソースはショボショボです。
もっと良いモデル構築方法があればぜひご指摘頂ければと思います。
# coding:utf-8
import numpy as np
import scipy.misc
import tensorflow as tf
from keras.utils import np_utils
from keras.models import Sequential, Model, model_from_json
from keras.layers.core import Dense, Activation, Flatten, Dropout
from keras.layers.convolutional import Convolution2D
from keras.layers.convolutional import MaxPooling2D
from keras.optimizers import SGD
from keras.layers.normalization import BatchNormalization
from keras.callbacks import EarlyStopping, TensorBoard, ModelCheckpoint
from keras.utils.visualize_util import plot
import keras.backend.tensorflow_backend as KTF
import matplotlib.pyplot as plt
#1024個の一層目を定義
in_shape = (32, 32, 3) #縦、横、RGB
#クラスを指定
categories = ["aya ueto", "ayame gouriki", "mayu watanabe", "nozomi sasaki","yui aragaki"]
nub_classes = len(categories)
#モデルの作成
def build_model():
model = Sequential()
#畳み込み層の作成
#1層目の追加 1024個の層を最初に作り、フィルター3*3のフィルターを32個作成
model.add(Convolution2D(32, 3, 3, border_mode="same", input_shape=in_shape))
model.add(Activation("relu"))
#2層目の畳み込み層
model.add(Convolution2D(32, 3, 3, border_mode="same"))
model.add(Activation("relu"))
#プーリング層
model.add(MaxPooling2D(pool_size=(2, 2)))
#Dropoutとは過学習を防ぐためのもの 0.25は次のニューロンへのパスをランダムに1/4にするという意味
model.add(Dropout(0.5))
#3層目の作成
model.add(Convolution2D(64, 3, 3, border_mode="same"))
model.add(Activation("relu"))
#4層目の作成
model.add(Convolution2D(64, 3, 3, border_mode="same"))
model.add(Activation("relu"))
#プーリング層
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
#5層目
model.add(Convolution2D(128, 3, 3, border_mode="same"))
model.add(Activation("relu"))
#6層目
model.add(Convolution2D(128, 3, 3, border_mode="same"))
model.add(Activation("relu"))
#プーリング層
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
#平坦化
model.add(Flatten())
#7 全結合層 FC
model.add(Dense(100))
model.add(Activation("relu"))
#Dropout
model.add(Dropout(0.5))
#8層目 引数nub_classesとは分類の数を定義する。
model.add(Dense(nub_classes))
model.add(Activation('softmax'))
#ここまででモデルの層完成
#lossは損失関数を定義するところ
model.compile(loss="categorical_crossentropy",
metrics = ["accuracy"],
optimizer = "adam"
)
#学習モデル図の作成
plot(model, to_file='model.png')
return model
def plot_history(history):
# 精度の履歴をプロット
plt.plot(history.history['acc'],"o-",label="accuracy")
plt.plot(history.history['val_acc'],"o-",label="val_acc")
plt.title('model accuracy')
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.legend(loc="lower right")
plt.show()
# 損失の履歴をプロット
plt.plot(history.history['loss'],"o-",label="loss",)
plt.plot(history.history['val_loss'],"o-",label="val_loss")
plt.title('model loss')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(loc='lower right')
plt.show()
if __name__ == "__main__":
#ここに読み込み処理と関数呼び出しを行う
#cifar10からデータを取得 10種類の画像データセットがある 計5万枚
#(X_train, y_train), (X_test, y_test) = np.load("./idol_makedata/idol.npy")
X_train, X_test, y_train, y_test = np.load("./idol_makedata/idol.npy")
print(X_train.shape, y_train.shape)
print(X_test.shape, y_test.shape)
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)
X_train = X_train.astype('float32') / 255
X_test = X_test.astype('float32') / 255
print("X_train", X_train.shape)
print("y_train", y_train.shape)
print("X_test", X_test.shape)
print("y_test", y_test.shape)
#ここからが上記で作成したモデルを呼び出す処理
model = build_model()
history = model.fit(X_train, y_train,
nb_epoch=30, #学習させる回数 今回は10 回数はお好みで pythonのnb_epochとはrangeの繰り返しのこと
batch_size=500, #無作為に何枚学習に使用するか決定する。数字はなんでも良い
validation_data=(X_test, y_test)
)
#学習モデルの保存
json_string = model.to_json()
#モデルのファイル名 拡張子.json
open('./idol_makedata/idol.json', 'w').write(json_string)
#重みファイルの保存 拡張子がhdf5
hdf5_file = "./idol_makedata/idol-model.hdf5"
model.save_weights(hdf5_file)
# モデルの評価evaluate
score = model.evaluate(X_train, y_train)
print("test loss", score[0])
print("test acc", score[1])
# modelに学習させた時の変化の様子をplot
plot_history(history)
それでもある1人の人物検出が正しくできない
なぜか不明。
ある1人の誤検知が多く、残り4人はまあまあな感じです。
誤検知多い1人については学習データ悪いのか、モデルが悪いのか、原因がわかりません。
学習データを入れ替えるなどして再分析して見る必要がありそうです。(今のところその気力なし)
また気が向いた時に見直してみたいと思います。
その他の物体検出記事はこちらから
それではまた。













この記事へのコメントはありません。