


目次
wikipedia日本語全文データから類義語を話すSlackbotを作った話
こんにちは。
AI coordinatorの清水秀樹です。
前回の記事で日本語を学習するマルコフ連鎖を使ったSlackbotを作成しました。
ただこのSlackbotは生成される日本語の品質がイマイチなので、今度はwikipediaの日本語全文データを学習したモデルで類義語を話すSlackbotを作ってみました。
興味がある方は参考にしてみてください。
開発環境
macOS Sierra
Anaconda3-4.2.0-MacOSX-x86_64
python 3.5.2
Slackbotの作り方
前回の記事「言葉を自動学習するSlackbotをマルコフ連鎖で実装」を参考にSlackbotを作成してみてください。
割と簡単に作成できますので、bot入門としては良い練習になるかと思います。
これ以降の記事は、ここでSlackbotを作っていることを前提にお話しします。
wikipedia日本語全文データを学習したモデルの作成方法
こちらも以前紹介した「wikipedia全文データからWord2Vecで類義語を抽出してみる」を参考に学習モデルを作成してください。
この記事ではコマンドラインから類義語を答える仕組みを構築しましたが、今回はこれをSlackbotから答えるようにしてみます。
モデルの作成が完了するとファイルが3種類出来上がります。
- wiki.model
- wiki.model.syn1neg.npy
- wiki.model.wv.syn0.npy
今回はこの3つのデータを使用します。
ソースコードの変更
修正するソースコードは、my_mention.py のみです。
以下のように修正してください。
そのまま貼り付けて上書きして大丈夫です。
# coding: utf-8
from slackbot.bot import default_reply
from janome.tokenizer import Tokenizer
import os, re, json, random
from gensim.models import word2vec
# 入力メッセージを取得し、slackbotに返事をさせる
@default_reply()
def default_func(message):
text = message.body['text'] # メッセージを取り出す
model = word2vec.Word2Vec.load('./plugins/wiki.model')
#res = model.most_similar(positive = )[0]
#print(res[0])
#message.reply(res[0])
res = model.most_similar(positive = )
n = [w[0] for w in res]
print(text,"=", ",".join(n))
message.reply(" , ".join(n))
Slackbotの起動
以下のコマンドでSlackbotを起動しましょう。
$ python3 run.py
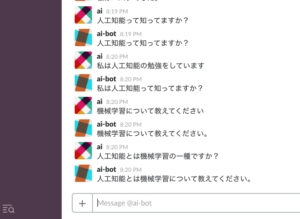
起動したら適当に単語を入力してみると、類義語を返してくれます。

少し応答が遅いですが、割と簡単に作成できました。
その他の自然言語処理記事はこちらから
それではまた。














この記事へのコメントはありません。