

マルコフ連鎖とは
こんにちは。
AI coordinatorの清水秀樹です。
簡単に説明すると、マルコフ連鎖を使用すれば既存の文章を元にして自動で文章を生成することができるようになります。
ロシアの数学者マルコフによって研究されたモデルだそうです。
このモデルには物理学や統計学が使われているようです。
まあ、難しいことはよく分かりませんが、使って見ることでその効果を確認していきたいと思います。
今回はひたすら対話を繰り返すことで、勝手に自動学習していくSlackbotを作成します。
開発環境
macOS Sierra
Anaconda3-4.2.0-MacOSX-x86_64
python 3.5.2
参考にさせて頂いたサイトと書籍の紹介
Slackbotを作成する上で、下記サイトを参考にさせて頂きました。
PythonのslackbotライブラリでSlackボットを作る
マルコフ連鎖については以下の書籍を参考にさせて頂いています。
書籍名:Pythonによるスクレイピング&機械学習
書籍の詳細についてはこちら
Slackbotの環境準備
基本的Slackbotの作成方法は参考元サイトの通りで実装できますが、ハマった点だけを紹介します。
まずはbotにするユーザーを登録する必要がありますでの、グループを作成しただけではユーザーが自分しかいません。
そのためbot用にユーザーを紹介しましょう。
続いて、API_TOKENの取得方法です。
こちらもググればすぐに取得方法が分かると思いますので、ここでは紹介を割愛します。
開発用のフォルダ構成は以下の通りです。
slackbot # プログラムをまとめるディレクトリ。名前はなんでも良い ├─ run.py # このプログラムを実行することで、ボットを起動する ├─ slackbot_settings.py # botに関する設定を書くファイル └─ plugins # botの機能はこのディレクトリに追加する ├─ __init__.py # モジュールを示すためのファイル。空で良い └─ my_mention.py # 機能を各ファイル。任意の名前で良い
参考元サイトの丸パクリです。
ソースコードは以下の通りです。
参考元と異なる部分のみ紹介します。
slackbot_settings.py
# coding: utf-8 # botアカウントのトークンを指定 API_TOKEN = "xxxxxxxxxxxxxxxxxxxxxxxxxxx" # プラグインスクリプトを置いてあるサブディレクトリ名のリスト PLUGINS = ['plugins']
API_TOKENは取得したトークンを指定してください。
マルコフ連鎖
my_mention.py のソースコードにマルコフ連鎖を実装しています。
# coding: utf-8
from slackbot.bot import default_reply
from janome.tokenizer import Tokenizer
import os, re, json, random
# 自分で育てるbotモデル作成
dict_file = "chatbot-data.json"
dic = {}
tokenizer = Tokenizer() # janome
# 辞書があれば最初に読み込む
if os.path.exists(dict_file):
dic = json.load(open(dict_file,"r"))
# 辞書に単語を記録する
def register_dic(words):
global dic
if len(words) == 0: return
tmp = ["@"]
for i in words:
word = i.surface
if word == "" or word == "\r\n" or word == "\n": continue
tmp.append(word)
if len(tmp) < 3: continue
if len(tmp) > 3: tmp = tmp[1:]
set_word3(dic, tmp)
if word == "。" or word == "?":
tmp = ["@"]
continue
# 辞書を更新するごとにファイルへ保存
json.dump(dic, open(dict_file,"w", encoding="utf-8"))
# 三要素のリストを辞書として登録
def set_word3(dic, s3):
w1, w2, w3 = s3
if not w1 in dic: dic[w1] = {}
if not w2 in dic[w1]: dic[w1][w2] = {}
if not w3 in dic[w1][w2]: dic[w1][w2][w3] = 0
dic[w1][w2][w3] += 1
# 文章を生成する
def make_sentence(head):
if not head in dic: return ""
ret = []
if head != "@": ret.append(head)
top = dic[head]
w1 = word_choice(top)
w2 = word_choice(top[w1])
ret.append(w1)
ret.append(w2)
while True:
if w1 in dic and w2 in dic[w1]:
w3 = word_choice(dic[w1][w2])
else:
w3 = ""
ret.append(w3)
if w3 == "。" or w3 == "?" or w3 == "": break
w1, w2 = w2, w3
return "".join(ret)
def word_choice(sel):
keys = sel.keys()
return random.choice(list(keys))
# slackbotに返答させる
def make_reply(text):
# まず単語を学習する
if text[-1] != "。": text += "。"
words = tokenizer.tokenize(text)
register_dic(words)
# 辞書に単語があれば、そこから話す
for w in words:
face = w.surface
ps = w.part_of_speech.split(',')[0]
if ps == "感動詞":
return face + "。"
if ps == "名詞" or ps == "形容詞":
if face in dic: return make_sentence(face)
return make_sentence("@")
# 入力メッセージを取得し、slackbotに返事をさせる
@default_reply()
def default_func(message):
text = message.body['text'] # メッセージを取り出す
res = make_reply(text)
message.reply(res)
対話を続ければ勝手に自動学習するようになっています。
学習モデルも chatbot-data.json に保存しますので、処理を中断しても継続して再利用することができます。
学習結果の検証
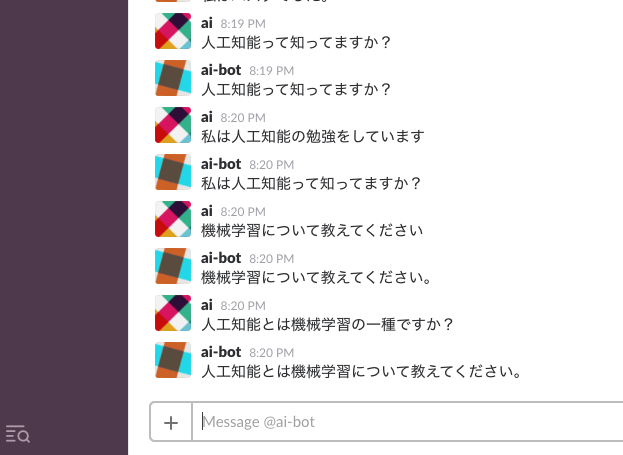
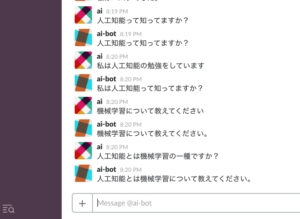
ひたすら機械学習について対話をして見ました。
起動方法はターミナルで起動します。
$ python3 run.py start slackbot
最初はおうむ返しになりますが、すでに既出済の単語を放り込むとSlackbotの反応が変わってきます。

・・・正直実用には絶えないでしょうね。
ただ、もう少し複雑にソースコードを組み込めば可能性もあるような気がします。
何かに特化した学習モデルを準備して自動学習しないように対応することも可能なので、そうすればバカにならず対話を続けることができるSlackbotも作れそうな気がします。
この辺はもう少し模索していきたいですね。
その他の自然言語処理記事はこちらから
それではまた。














この記事へのコメントはありません。