


目次
学習モデルの作成
こんにちは。
AI coordinatorの清水秀樹です。
サンプルソースコードのSSD_kerasを使ってリアルタイム映像からの物体検出ができるようになると、自分で学習させたモデルで物体検出をやりたくなります。
そこでどうやったら学習モデルが作成できるのかネットサーフィンをしていたら、データ準備がとても大変かつ難易度が高いことを知りました。
中ば途方に暮れていたところ、実際に自分で準備した画像を画像データ準備用のツールを開発することで、独自の学習モデルを作成していたサイトを見つけました。
そのサイトを参考に、筆者でもその方法で試してみたところ、色々苦労しながらも無事に物体検出をすることができましたので、個人的な備忘録の意味も兼ねて、その内容の紹介をしたいと思います。
できるだけ分かりやすく説明していますので、挑戦してみたい方は当記事を参考に学習モデルを作成してみてください。
参考にさせて頂いたサイトの紹介
今回参考にさせて頂いたサイトは以下の2サイトです。
分かりやすく説明くださっているので、筆者のような素人でもなんとか実装できました。
物体検出アルゴリズム(SSD : Single Shot MultiBox Detector)を学習させてみる
物体認識用データセット作成支援ツール(Faster R-CNNとかSSDとか)
また、もしこれからDeep Learningの勉強をするなら、こちらで紹介する書籍も参考になりますので一読してみることをオススメします。
テスト環境
macOS Sierra
Anaconda3-4.2.0-MacOSX-x86_64
python 3.5.2
opencv3 3.1.0
tensorflow-1.0.0
keras 1.2.2
画像データセットの準備方法
まず大量の画像が必要であることはいうまでもないのですが、過去記事で紹介していたような学習データではなく、xml形式の学習データが必要となります。
これが筆者を途方に暮れさせた原因です。
どんなデータかというと、以下のような画像を、

xml形式に変換する必要があるわけです。
<?xml version="1.0" encoding="UTF-8"?>
<annotation>
<folder>XXX</folder>
<filename>486499d6-ed3d-4c2c-88e2-4f742a0ff7e5.jpg</filename>
<source>
<database>XXX</database>
<annotation>XXX</annotation>
<image>XXX</image>
<flickrid>XXX</flickrid>
</source>
<owner>
<flickrid>XXX</flickrid>
<name>?</name>
</owner>
<size>
<width>340</width>
<height>214</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
</annotation>
上記xmlには、学習させたい物体の位置情報を記述する必要があります。
この例では顔の部分を選択した位置情報が記述されています。
このxmlデータをアノテーションデータと呼ぶそうです。
そしてこの画像アノテーションデータを簡単に作成できるツールを紹介しているのが、参考にさせて頂いたサイトに公開されているわけです。
Processing3.3を使って画像アノテーションデータを作成するわけですが、筆者はこのProcessingを使ったことがなく、導入に四苦八苦しました。
そんな方のために、どうやって使うのか紹介したいと思います。(備忘録も兼ねて)
まず、公式サイトからProcessing3.3をダウンロードしましょう。

今回は最新バージョンではなく、説明通りProcessing3.3を使用しました。
続いてProcessingを動かすソースコードをgithubからダウンロードしましょう。
さてここからハマったわけですが、どうやってソースコードを起動するか悩みました。
ここで紹介する動かし方が正しいかは不明ですが、筆者ができたやり方を紹介します。
まず、Processing3を起動します。
すると以下のような新規作成用の画面が起動しますので、この画面は無視して、「ファイル」>「開く」の順で、ダウンロードしたmainGUI.pdeを開いてください

するとポップアップが表示されて、なにやら質問されますが、okをクリックしてください。

ソースコードが読み込まれれば、以下のような画面になるので、

この画面に残りのソースコード2つ(getImage.pde、processXML.pde)をドラッグ&ドロップしてください。

3つのソースコードが入りました。
このままではまだ動きません。
今現在のフォルダ構成は以下の画像のようになっているはずです。

mainGUIフォルダが作成されていて、その配下に3つのソースコードができています。
このmainGUIフォルダにダウンロード時に付属していたxmlフォルダをコピーすれば起動できます。

上記フォルダ構成になったら、Processing画面の左上の右矢印ボタンを押下しましょう。

起動できました。
筆者はここに行き着くまでに、数時間かかりました。
Processingが起動できたら実際の画像アノテーションデータの作り方については、参考元サイトのデモ動画を確認して頂ければ、使い方が分かると思います。
独自画像を学習させる前にまずは基本動作から
ここまで出来ると、自分で準備した画像で早速学習させてみたいのですが、まずはすでに準備されている学習データから学習してみましょう。
いきなり難しいことにチャレンジしてつまずくよりも、基本的な流れを把握してからチャレンジした方が、結果的に早くできます。
(筆者の場合ですが・・・)
学習データのダウンロード
The PASCAL Visual Object Classes Homepageに学習用データが準備されています。
今回は「The VOC2007 Challenge」を使用しましたので、「The VOC2007 Challenge」をクリックして次画面に進んでください。

次の画面に進んだら、真ん中あたりから学習用データをダウンロードできます。
450Mサイズなのでわりと量があります。

ダウンロードしたら、ファイルを展開しましょう。
ソースコードの準備
これがまた結構大変でした。
筆者の理解が足りないせいで時間がかかりましが、参考元サイトにも記載があるように、フォルダ構成や各ライブラリーのバージョンには注意が必要です。
これが出来ていなかったばっかりに苦労しました。
フォルダ構成は注意すれば良いのですが、各ライブラリーのバージョンについては、自分で修正する気が無いなら、上記で紹介しているテスト環境通りのバージョンに揃えておいた方がトラブルなくスムーズに学習できるかと思います。
学習のさせ方については参考元サイトをご覧ください。
ちなみに筆者の環境ではGPUを使用していないため、Epoch=2でやりました。(少な!!)
学習モデルを作成してみることが目的なので、学習精度よりもスピード重視で動かしました。
これでも数時間かかりました。(夜に実行して、翌朝完了していた。実際はもっと早いと思います。)
真面目に開発するなら、マシンパワーが必要になります。
学習データからの物体検出
無事に学習が完了したら、実際に自分が作成した学習モデルで物体検出をやってみましょう。
実行の仕方については、映像物体検出を簡単に実装する方法 for maxOSを参考にしてください。
これで動かすことが出来たら、次はいよいよ独自画像で学習モデルを作成していきます。
独自画像でのデータ準備開始
これは地道にやっていくしかありません。
Processingを起動して、デモ動画を参考にアノテーションデータを作成していきましょう。
今回は上戸彩さんの画像で試してみます。

画像アノテーションデータはこんな感じです。
<?xml version="1.0" encoding="UTF-8"?>
<annotation>
<folder>XXX</folder>
<filename>100011.jpg</filename>
<source>
<database>XXX</database>
<annotation>XXX</annotation>
<image>XXX</image>
<flickrid>XXX</flickrid>
</source>
<owner>
<flickrid>XXX</flickrid>
<name>?</name>
</owner>
<size>
<width>279</width>
<height>356</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>aya ueto</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>1</difficult>
<bndbox>
<xmin>71</xmin>
<ymin>37</ymin>
<xmax>179</xmax>
<ymax>160</ymax>
</bndbox>
</object>
</annotation>
pklファイルの作成
get_data_from_XML.pyのソースコードを変更しましょう。
42行目からラベル名の指定となっています。
今回はクラス数はそのままの20とし、独自画像だけでpklファイルを作成しました。
つまり、もともとあったデータは使用せず、準備したデータだけでpklファイルを作成しています。
画像アノテーションデータと実際の画像については、VOCdevkit/VOC2007内にあるAnnotationsフォルダ、JPEGImagesフォルダに入れてpklファイルを作成しています。
ソースコードの”num_classes”は、上戸彩さんの画像アノテーションデータしか準備していないので、num_classes=1にする方法が正しいと思うのですが、これだとなぜかうまく学習が終了しませんでした。
そのため、もともとあった20クラスの一番上に定義してある”aeroplane”を”aya ueto”に変更して試してみました。
おそらく正しいやり方では無いと思いますが(ていうか絶対正しく無い!)、これでもしっかり動きましたので一旦良しとしました。
独自画像の学習モデル作成
pklファイルが作成出来たら、tarin.pyを実行しましょう。
特に修正は必要ありません。
今回準備した画像は22枚で、Epoch = 10 で学習せさました。
なんせGPUで実行していないので、学習精度よりも学習モデルを作成することを優先しました。
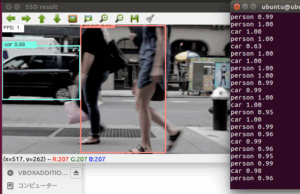
学習が完了すると、1枚画像が表示されて物体検出の結果を出力してくれます。

中々良い感じで物体検出が出来たようです。
映像からの物体検出
学習モデルが作成出来たら、SSD_Kerasで早速試してみましょう。
無事に映像から物体検出が出来て入ればひとまず成功です。
学習したモデルは、checkpointsフォルダにEpochの数分作成されています。
一番新しい学習モデルを使用しましょう。
videotest_example.pyのソースコードも修正が必要です。
クラス名の変更が必要になりますので、”aeroplane”を”aya ueto”に変更してから実行してください。
実行した結果

ようやく出来た。

ん!?

学習精度が低いのは否めない感じです。
その他の物体検出記事はこちらから
それではまた。
トップページへ













コメント返信いただけるかわかりませんがこちらを参考に行わせていただいた結果
初期エポックのlossが4.〇〇と大きすぎて普段ではありえない数字になったのですがこれは正しいのでしょうか?
私もGPUがサポートされていないため時間がかかるので23枚10epochで行なって見ましたが検出がうまくいきませんでした…。
初めまして。
初期エポックは筆者の場合、もっとひどかったですね。
学習モデルを作成することを目標にしていたため、lossについての精度はほとんどシカトしてました。
以下、筆者が実行した際の参考値です。
Epoch 1/10
20/22 [==========================>…] – ETA: 4s – loss: 8.1154
:
Epoch 10/10
20/22 [==========================>…] – ETA: 4s – loss: 0.9624
誤認識は多いですが、全く検出できないこともありませんでした。
質問に対して、正しいかどうかは筆者も正直わかりませんが、精度を求めるなら、やはり画像数とEpoch数を増やすなどの工夫が必要かなと思っています。
ありがとうごさいます。
独自データを作成しようとしたところ、
unknown label: aeroplane
unknown label: aeroplane
unknown label: aeroplane
unknown label: aeroplane
・・・
となってしまいます。
Deeplearning素人なので申し訳ありませんが、おしえていただけないでしょうか?
ありがとうごさいます。
独自データを作成しようと、
get_data_from_XML.pyを実行したところ、
unknown label: aeroplane
unknown label: aeroplane
unknown label: aeroplane
unknown label: aeroplane
・・・
となってしまいます。
もとからあるのAnotationsの.aeroplaneの.xmlファイルは、削除すべきですか?
Deeplearning素人なので申し訳ありませんが、おしえていただけないでしょうか?
業務統括管理担当様へ
はじめまして。
拓思科技株式会社の金時英と申します。
当社は2002年設立し、日本、欧州、中国、インド拠点のネットワーク活用にて、
日本と欧米の多くのお客様からお取引をいただいております。
まずは、両社の業務内容の共有化とAIビデオデータアノテーション業務のご相談を含み、
一度WEB会議のお時間をいただきたいと思います。
ご多用とは存じますが、下記候補日程にてweb会議のお時間をご調整賜れば幸甚でございます。
9月16日~20日
9月 23日~27日
11時~12時 14時~17時
お忙しいところ恐縮ですが、どうぞご検討のほどよろしくお願い申し上げます。