


目次
Deep Learningを活用したChatBot
こんにちは。
AI coordinatorの清水秀樹です。
Kerasを使ったChatBotの作成に挑戦したので、環境準備も含めて紹介します。
今回はすでに学習済みのデータを使用したChatBotの説明になります。
学習データの作り方については今後紹介していきたいと思います。
参考にさせて頂いたセミナー
今回の実装方法は、AI Academyが主催するセミナーで学習した内容になります。
より深く学習したい方はAI Academyの「人工知能に特化したオンラインプログラミングスクール」を受講してみるとより理解が深まることでしょう。
定期的にセミナーを開催していますので、興味がある方はぜひ参加してみてください。
開発環境の準備
ubuntu16.4をベースに説明します。
python3.6を使用します。
Anaconda 4.3.1 For Linuxのインストール
python 3.6 Version 64-BIT INSTALLERをダウンロードします。
ダウンロードが完了したら、ターミナルからダウンロードしたディレクトリに移動して、以下のコマンドを入力してください。
この例ではダウンロードフォルダ内で実行しています。
cd ダウンロード bash Anaconda3-4.3.1-Linux-x86_64.sh
途中、yes/noを聞かれますが、全てyesで問題ありません。
インストールが完了したら、無事にインストールが完了しているか確認しましょう。
python35@python35:~$ conda -V conda 4.3.14
インストールしたバージョンが表示されます。
gensimのインストール
次はgensimをインストールします。
gensimは自然言語処理のためのライブラリです。
gensimのインストール方法は以下のコマンドをターミナルで打ち込むだけです。
少し時間がかかります。
$ conda install gensim途中で、Proceed ([y]/n)? と聞かれるので、yを選択してエンターを押下してください。
tensorflowインストール
続いてtensorflowのインストールです。
tensorflowははGoogleがオープンソースで公開している機械学習ライブライリーになります。
$ conda install tensorflow
途中で、Proceed ([y]/n)? と聞かれるので、yを選択してエンターを押下してください。
kerasのインストール
kerasのインストールはバージョン指定でインストールします。
最新のバージョンではうまく機能しませんでした。
対応が入るまでは旧バージョンで環境構築しましょう。
$ pip install https://github.com/fchollet/keras/tarball/1.2.2
以上で環境準備完了です。
学習済みデータからChatBotを動かしてみる
では早速動かしてみましょう。
import numpy as np
import gensim
import nltk
# 初回のみnltk.download(punkt)を定義してください。
nltk.download('punkt')
# 詳細は以下のサイトを参考にしてください。
# http://stackoverflow.com/questions/4867197/failed-loading-english-pickle-with-nltk-data-load
from keras.models import load_model
#学習データのロード
model=load_model('./data/LSTM5000.h5')
# word2vec.bin download link
# https://ibm.ent.box.com/s/77etivy69jmga0x0u6vs2n47ul8baks4
mod = gensim.models.Word2Vec.load('./data/word2vec.bin')
#BOT開始
x = input("you = ")
# 全て1を持つ300の行列を生成
sen = np.ones((300, ), dtype=np.float32)
# Word2vecでベクトル化するための前処理
sent = nltk.word_tokenize(x.lower())
# print(sent)
# ベクトル化処理する
sentvec = [mod[w] for w in sent if w in mod.wv.vocab]
if len(sentvec)<15:
for i in range(15-len(sentvec)):
sentvec.append(sen)
sentvec=np.array([sentvec])
# print(sentvec)
predictions = model.predict(sentvec)
outputlist = [mod.wv.most_similar([predictions[0][i]])[0][0] for i in range(15)]
# print(outputlist)
output =' ' .join(outputlist)
#kleiserとkarluahという文字列をスペースで置換する
output = output.replace("kleiser", " ")
output = output.replace("karluah", " ")
print("AI = " , output)
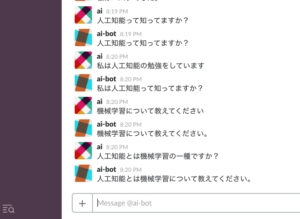
結果は以下の通り
you = how are you AI = i am doing all . that . ?
とりあえずAIから返事が来ました。
その他の自然言語処理記事はこちらから
それではまた!














この記事へのコメントはありません。