

目次
映像からの物体検出
こんにちは。
AI coordinatorの清水秀樹です。
リアルタイム映像からの物体検出に挑戦してみました。
ただし簡単にはできず、色々ハマってえらく苦労したので、同じ悩みを持っている人の助けになればと思い実装までの手順を記事にします。
この手順に則って環境準備から始めて頂ければ、素人でも自分のPC場で映像からの物体検出が実装できるようになります。
それでは始めてみましょう。
参考にさせて頂いたサイト
以下のサイトを参考にさせて頂きました。
SSD: Single Shot MultiBox Detector 高速リアルタイム物体検出デモをKerasで試す
こちらのサイトは素人の筆者でもなんとか実装できるぐらいまで丁寧に説明してくださっていますので、リアルタイムからの物体検出を実行する上で、大変参考になりました。
また、これからDeep Learningの勉強をするなら、こちらで紹介する書籍が参考になります。
まっさらなubuntu16.4の準備
まっさらな状態から始めましょう。
私はすでに色々なモジュールを組み込んでいたせいか、エラーばかり発生してまともにプログラムが動きませんでした。
そのため、ubuntuのインストールからやり直し、なんとか実装することができました。
無駄に苦労したくない方は、ubuntuをインストールしたまんまの環境を準備してください。
ubuntuのインストールはフリーのVirtualBoxで十分事足ります。
ちなみに筆者はimacで実装しました。
python3-pipのインストール
ubuntuのインストールが完了したら、python3系のpipのインストールから始めましょう。
ターミナルを起動し、以下のコマンドを打ち込みます。
$ sudo apt-get install python3-pip python3-dev
tensorflow-1.1.0のインストール
続いてtensorflow-1.1.0のインストールです。
バージョンは非常に重要です。
これにハマりました。
結局動いたバージョンが、tensorflow-1.1.0でした。
今回はGPUを使用しないので、以下のコマンドでtensorflowをインストールしてください。
$ pip3 install tensorflow==1.1.0
keras-1.2.2のインストール
続いてkeras-1.2.2のインストールです。
最新版のバージョン2をインストールしてしまいますと、全く動きません。
自力で直せない方は、keras-1.2.2をインストールしましょう。
筆者はここでも苦労しました。
結局バージョン2は筆者の実力ではどうにもできませんでした。
$ sudo pip3 install keras==1.2.2
opencvのインストール
opencvはたくさんのコマンドからインストールすることになります。
anacondaの一発インストールではうまく行きませんでした。
それに、そこそこ時間がかかります。
imac2012のVirtualBox ubuntuインストール版では約1時間ぐらいかかりました。
以下のコマンドを順番に打ち込んでください。
$ sudo apt-get install --assume-yes build-essential cmake git $ sudo apt-get install --assume-yes build-essential pkg-config unzip ffmpeg qtbase5-dev python-dev python3-dev python-numpy python3-numpy $ sudo apt-get install --assume-yes libopencv-dev libgtk-3-dev libdc1394-22 libdc1394-22-dev libjpeg-dev libpng12-dev libtiff5-dev libjasper-dev $ sudo apt-get install --assume-yes libavcodec-dev libavformat-dev libswscale-dev libxine2-dev libgstreamer0.10-dev libgstreamer-plugins-base0.10-dev $ sudo apt-get install --assume-yes libv4l-dev libtbb-dev libfaac-dev libmp3lame-dev libopencore-amrnb-dev libopencore-amrwb-dev libtheora-dev $ sudo apt-get install --assume-yes libvorbis-dev libxvidcore-dev v4l-utils
Open Source Computer Vision Libraryのダウンロード
以下のサイトからライブラリーを一式ダンロードします。
$ git clone https://github.com/opencv/opencv.git $ cd opencv
ダウンロードが完了したらbuildします。
$ mkdir build $ cd build/ $ cmake -D CMAKE_BUILD_ENGINE=RELEASE -D CMAKE_INSTALL_PREFIX=/usr/local -D WITH_TBB=ON -D WITH_V4L=ON -D WITH_QT=ON -D WITH_OPENGL=ON -D WITH_CUBLAS=ON -DCUDA_NVCC_FLAGS="-D_FORCE_INLINES" .. $ make -j $(($(nproc) + 1))
インストールしましょう。
$ sudo make install $ sudo /bin/bash -c 'echo "/usr/local/lib" > /etc/ld.so.conf.d/opencv.conf' $ sudo ldconfig $ sudo apt-get update
jupyter notebookのインストール
pythonを実行する上で便利なjupyter notebookをインストールしましょう。
$ sudo pip3 install jupyter notebook
ssd_kerasのダウンロード
ssd_kerasは映像からの物体検出を可能とするライブラリー群になります。
これを公開してくださった方に感謝ですね。
こちらのライブラリーをダウンロードして、映像からの物体検出を行うことになります。
$ git clone https://github.com/rykov8/ssd_keras.git $ cd ssd_keras
学習済みモデルは個別にサイトからダウンロードする必要があります。
ダウンロードする場所は、以下の画面を参考にしてください

クリックして、しばらく読み込みが始まった後に以下の画面が表示されますので、weights_SSD300.hdf5をダウンロードしてください。
これが学習モデルになります。

以上で環境準備は完了です。
サンプル写真からの物体検出
環境準備が完了したら、早速サンプルソースを使って物体検出を試してみましょう。
さきほどインストールしたjupyter notebookを使用します。
ダウンロードしたssd_kerasディレクトリに移動してjupyter notebookを起動してください。
$ cd '/home/ubuntu/ssd_keras' $ jupyter notebook
実行するファイルは、SSD.ipynb です。

SSD.ipynbを起動したら実行しましょう。

するとmatplotlib.pyplotがimportできないと叱られます。
もし上記のようなエラーが発生した場合は、以下のコマンドでmatplotlibをインストールしてください。
$ sudo pip3 install matplotlib
再度実行し直すと、またまた以下のようなエラーになります。

こちらも上記画像と同じようなエラーになった場合は、h5pyをインストールすれば解消します。
以下のコマンドでインストールしてください。
$ sudo pip3 install h5py
3度目の正直で再度実行し直せば、今度は動くはずです。
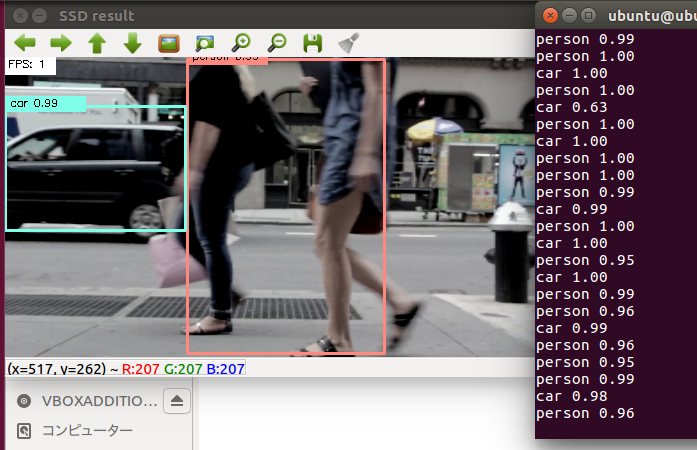
無事に動くと以下のようにサンプル画像から物体を検出した画像が表示されます。

ここまでできたら、映像からの物体検出ができる条件が整ったことを意味します。
早速挑戦。でもその前に
早速、映像の物体検出をやりたいところですが、サンプルソースに誤りがあります。
まずはそれを修正しましょう。
ssd_keras/testing_utils/videotest.pyの87行目に以下のロジックがあります。
vidw = vid.get(cv2.cv.CV_CAP_PROP_FRAME_WIDTH) vidh = vid.get(cv2.cv.CV_CAP_PROP_FRAME_HEIGHT)
このロジックを以下のように修正してください。
vidw = vid.get(cv2.CAP_PROP_FRAME_WIDTH) vidh = vid.get(cv2.CAP_PROP_FRAME_HEIGHT)
物体検出結果をターミナルで確認したい場合は、162行目に以下のprint文を追加してください。
print(text)
続いて動画ファイルの指定です。
動画ファイルの指定は、ssd_keras/testing_utils/videotest_example.pyで指定します。
24行目にファイルのパスを指定しているロジックがありますので、再生したいファイルのパスを指定してください。
vid_test.run('path/to/your/video.mkv')
以上で準備完了です。
videotest_example.pyの実行
では動かしてみましょう。
ディレクトリを移動して、videotest_example.pyを起動します。
$ cd testing_utils $ python3 videotest_example.py
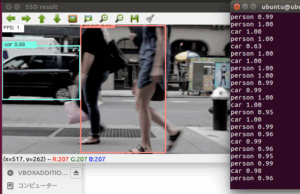
以下のように映像と物体検出している様子が確認できるはずです。

GPU仕様ではないのでFPSが1という、とてつもなく遅い動画となりましたが、なんとか動くはずです。
頑張って実装してみてください。
その他の物体検出記事はこちらから
それではまた。













私も同じくKeras 2.1.1ではまりました。
今日ググったら、https://github.com/pierluigiferrari/ssd_kerasを見つけました。Keras 2.X対応だと書いてますので、こちらのやり方では動く可能性があります。
私もこれから試してみます。
toruwestさん
管理人清水です。
貴重な情報連携ありがとうございます。
私も試してみたいと思います。
Keras2.1.1で動かせれば色々環境面でも助かりますね。
管理人様
当サイトを拝見し,ssdを実行してみたいと思い途中まで行ったのですが
「Open Source Computer Vision Libraryのダウンロード」の過程の
make -j $(($(nproc) + 1))の実行途中で「デバイスに空き容量がありません」と表示され最後まで実行できませんでした.
おそらく仮想環境(virtual box, ubuntu)の割り当てが少ないためであると考えているのですが,管理人様はどの程度の容量を割り当てたのでしょうか?
お忙しいところ誠に申し訳ございませんが,ご返信いただけると幸いです.
どうぞよろしくお願い致します.