

目次
YOLO v2をどうしてもPythonで使ってみたかったので作ってみた
こんにちは。
AI coordinatorの清水秀樹です。
数多くあるオブジェクト物体検出の中で、処理速度が最も早い?と言われているYOLO v2を試してみました。
公式サイトの通りやって、環境のセットアップと静止画のオブジェクト物体検出を描画できるところまでは簡単にできましたが、なぜか動画になるとエラーになってしまいました。
そんなわけで、公式サイトのやり方ではイマイチ不良消化のまま先に進めなくなってしまったので、少し思考を変え、静止画でオブジェクト物体検出ができるなら、Pythonでソースコードを組み直せば、リアルタイム映像でもYOLOを試せると考え、実際にPythonで動かせるように作成してみました。
中々苦労しましたが、なんとか実装できたので、その内容を紹介したいと思います。
参考にさせて頂いたサイトの紹介
ちょうど自分がやりたいことに近しいソースコードがGithubに紹介されていたので、参考にさせて頂きました。
上記以外でも、KerasバージョンやChianerバージョンもあるみたいなので、そのうち試してみたいと思います。
開発環境
macOS Sierra
Anaconda3-4.2.0-MacOSX-x86_64
python 3.5.2
opencv3 3.1.0
tensorflow 1.1.0
YOLO セットアップ方法
いつもセットアップに試行錯誤することが多いのですが、今回は割と簡単に準備できました。
とはいえ、つまずいた部分も少なからずあるので、解消法も含めて紹介します。
まずはGithubからクローンしましょう。
そしてクローンしたフォルダに入ります。
git clone https://github.com/thtrieu/darkflow.git cd darkflow
続いてYOLOの公式サイトからweightファイルをダウンロードします。
以下画像内のhere(258MB)をクリックするとダウンロードできます。

ダウンロードしたら、darkflow-masterフォルダ内にbinフォルダを作成し、binフォルダ内にyolo.weightsを保存しましょう。
続いてインストール作業になります。
以下の3つのコマンドうちいずれかでインストールができます。
python3 setup.py build_ext --inplace
pip install -e .
pip install .
正直、この3つ違いはよくわかりません。
筆者は一番上を使いました。
インストールができたら、早速サンプルソースコードを使って、静止画からのオブジェクト物体検出にチャレンジしてみましょう。
from darkflow.net.build import TFNet
import cv2
options = {"model": "cfg/yolo.cfg", "load": "bin/yolo.weights", "threshold": 0.1}
tfnet = TFNet(options)
imgcv = cv2.imread("./sample_img/dog.jpg")
result = tfnet.return_predict(imgcv)
print(result)
筆者はここで以下のエラーが発生しました。
module 'pandas' has no attribute 'computation'
ググって解決策を発見。
以下のコマンドでエラーを解消しました。
pip install dask --upgrade
が・・・・しかし、また別のエラー
/Users/hideki/darkflow-master/darkflow/net/flow.py in return_predict(self, im)
71 def return_predict(self, im):
72 assert isinstance(im, np.ndarray), \
---> 73 'Image is not a np.ndarray'
74 h, w, _ = im.shape
75 im = self.framework.resize_input(im)
AssertionError: Image is not a np.ndarray
よく確認してみると、パス名が違うじゃね〜か!!
imgcv = cv2.imread("./sample_img/dog.jpg")
ではなく、
imgcv = cv2.imread("./sample_img/sample_dog.jpg")
でした。
パス名を変更して実行すると無事処理が完了。
print(result)の結果から、以下のような情報が出力されました。
[{'confidence': 0.84485036, 'topleft': {'x': 81, 'y': 114}, 'label': 'bicycle', 'bottomright': {'x': 553, 'y': 466}}, {'confidence': 0.7951023, 'topleft': {'x': 462, 'y': 81}, 'label': 'truck', 'bottomright': {'x': 693, 'y': 167}}, {'confidence': 0.27549446, 'topleft': {'x': 59, 'y': 76}, 'label': 'motorbike', 'bottomright': {'x': 114, 'y': 124}}, {'confidence': 0.12680262, 'topleft': {'x': 139, 'y': 197}, 'label': 'cat', 'bottomright': {'x': 314, 'y': 551}}, {'confidence': 0.76959199, 'topleft': {'x': 136, 'y': 214}, 'label': 'dog', 'bottomright': {'x': 322, 'y': 539}}]
JSON形式で結果が返ってくるようです。
さて、ここまででセットアップ完了です。
リアルタイム映像からのオブジェクト物体検出にチャレンジ
では、目的のtensorflowとPythonを使ったリアルタイム映像からのオブジェクト物体検出にチャレンジしてみたいと思います。
オブジェクトごとに矩形の色を変えてみるなど、ちょっと頑張って作ってみました。
紹介しいているソースコードはPCのwebカメラで動くように作成しています。
また、confidenceが0.6以上のものに対してだけ、矩形するようにしています。
この辺はお好みで変更してください。
from darkflow.net.build import TFNet
import cv2
import numpy as np
options = {"model": "cfg/yolo.cfg", "load": "bin/yolo.weights", "threshold": 0.1}
tfnet = TFNet(options)
# カメラの起動
cap = cv2.VideoCapture(0)
class_names = ['aeroplane', 'bicycle', 'bird', 'boat', 'bottle',
'bus', 'car', 'cat', 'chair', 'cow', 'diningtable',
'dog', 'horse', 'motorbike', 'person', 'pottedplant',
'sheep', 'sofa', 'train', 'tvmonitor']
num_classes = len(class_names)
class_colors = []
for i in range(0, num_classes):
hue = 255*i/num_classes
col = np.zeros((1,1,3)).astype("uint8")
col[0][0][0] = hue
col[0][0][1] = 128
col[0][0][2] = 255
cvcol = cv2.cvtColor(col, cv2.COLOR_HSV2BGR)
col = (int(cvcol[0][0][0]), int(cvcol[0][0][1]), int(cvcol[0][0][2]))
class_colors.append(col)
def main():
while(True):
# 動画ストリームからフレームを取得
ret, frame = cap.read()
result = tfnet.return_predict(frame)
for item in result:
tlx = item['topleft']['x']
tly = item['topleft']['y']
brx = item['bottomright']['x']
bry = item['bottomright']['y']
label = item['label']
conf = item['confidence']
if conf > 0.6:
for i in class_names:
if label == i:
class_num = class_names.index(i)
break
#枠の作成
cv2.rectangle(frame, (tlx, tly), (brx, bry), class_colors[class_num], 2)
#ラベルの作成
text = label + " " + ('%.2f' % conf)
cv2.rectangle(frame, (tlx, tly - 15), (tlx + 100, tly + 5), class_colors[class_num], -1)
cv2.putText(frame, text, (tlx, tly), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0,0,0), 1)
# 表示
cv2.imshow("Show FLAME Image", frame)
# escを押したら終了。
k = cv2.waitKey(10);
if k == ord('q'): break;
cap.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
main()
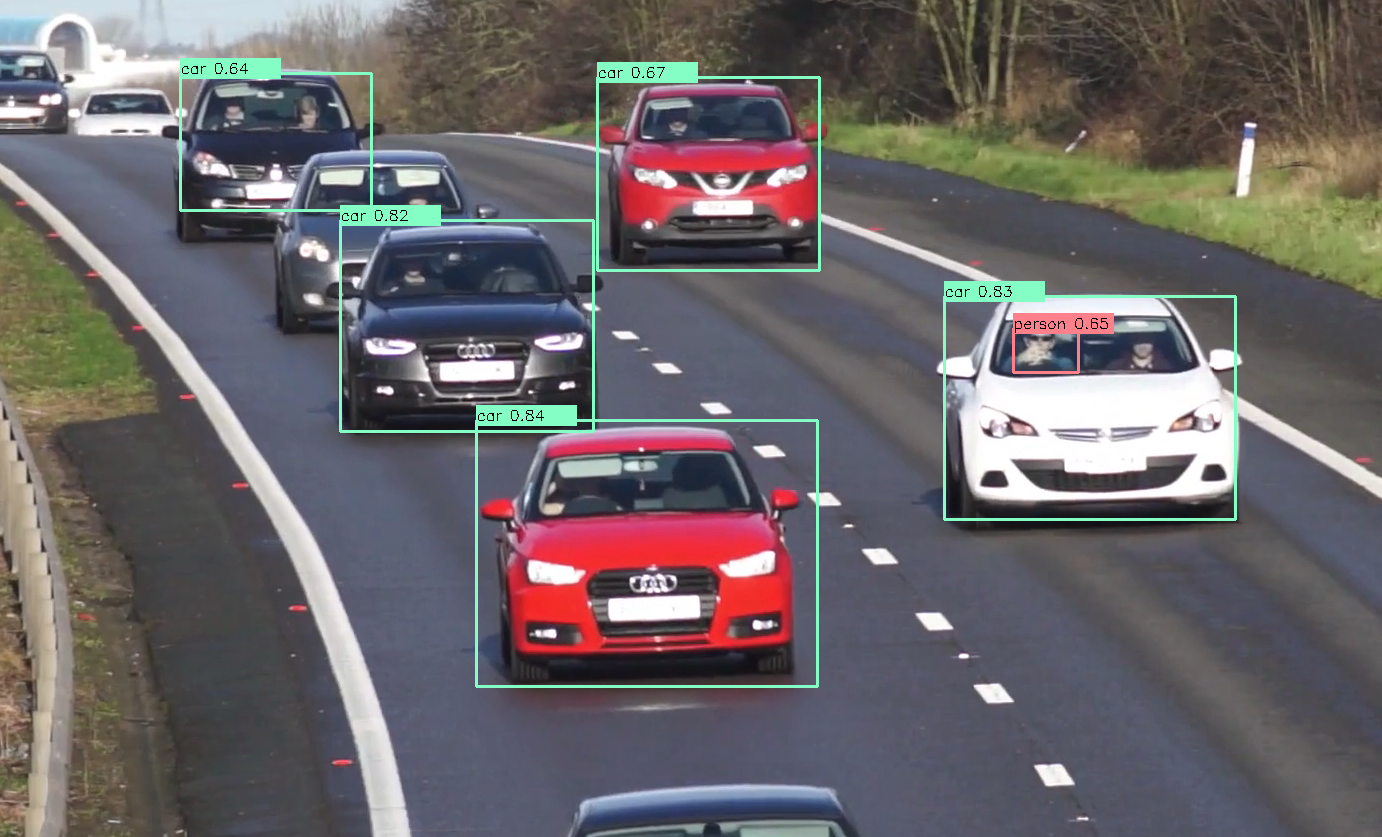
もちろん動画でも対応可能です。

車の中の人まで認識できるところがすごいですね。
ただ、処理速度に関して言うと、筆者の開発環境ではSSD_kerasと大差ない感じでした。
まとめ
最近は色々なオブジェクト物体検出方法が紹介されています。
次から次へと色々な技術が紹介されていて、しかも自分のPCでも試せるような時代になっているので、便利な世の中になったなぁ〜なんて感じています。
興味がある方はこのYOLOを使ったオブジェクト物体検出にチャレンジしてみてください。
また、これからDeep Learningの勉強をするなら、こちらで紹介する書籍も参考になりますので一読してみることをオススメします。
その他の物体検出記事はこちらから
それではまた。












darkflow-masterフォルダー内にbinファイルをつくるのではなく、darkflowフォルダー内にbinファイルをつくるのですね。
ソース上のパスの指定方法で、binファイルの保存場所を変更できますね。
darkflowで自前のデータで学習する記事を書いてくれませんか?